GPT-4.1 performance leap explained
GPT-4.1 performance benchmarks show surprising gains, but what do they hide? Our deep dive into training reveals tradeoffs.

GPT-4.1 performance numbers landed on my screen at 10:47 AM on Monday, and by 10:52 AM I had already yelled at my coffee mug. That is not normal. What OpenAI rolled out late on April 28, 2025, is not a routine model refresh. It is a direct, taunting challenge to everyone who has been saying that large language models have plateaued. The company released three new models: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano. And the flagship GPT-4.1 performance leap is so stark in the benchmarks that it makes GPT-4o look like a beta product from two years ago. Let me be extremely clear about what this is. This is the moment the AI arms race just yanked the steering wheel hard to the right.
The Cold Hard Numbers That Matter
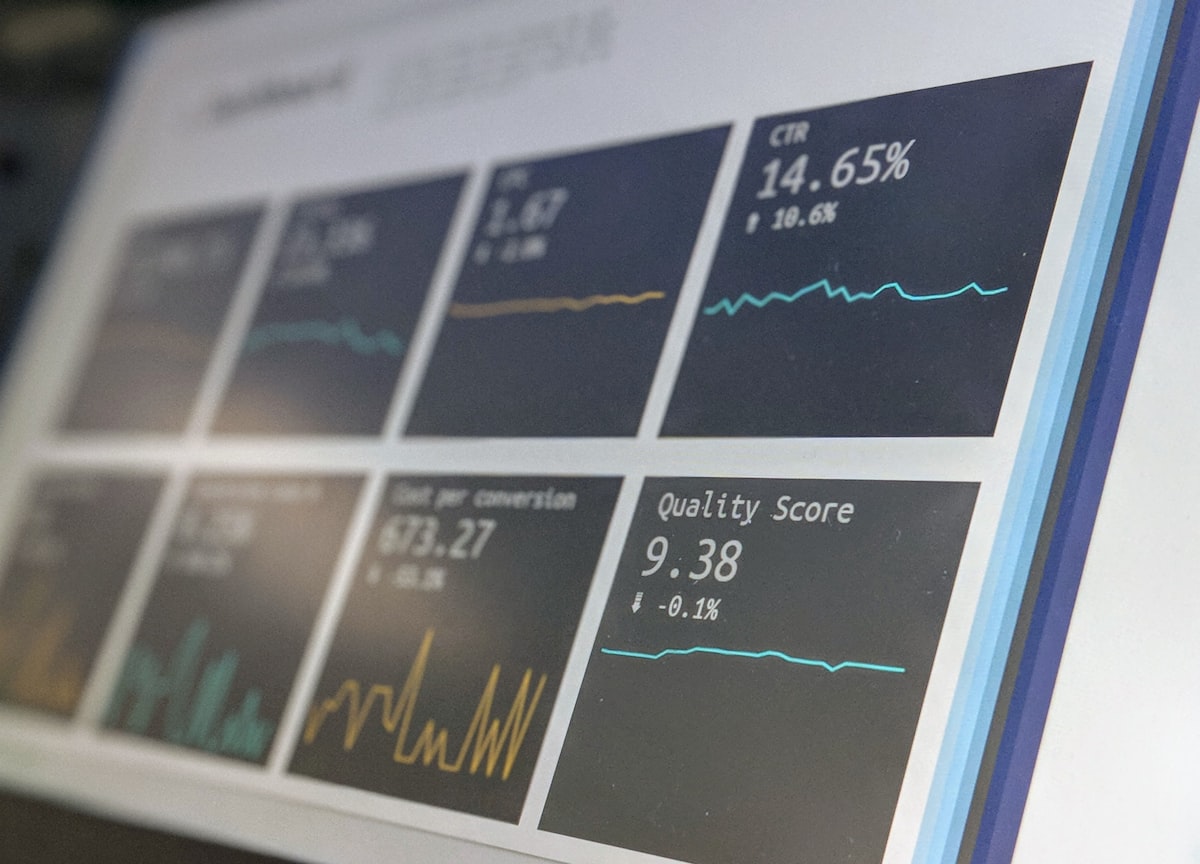
OpenAI published the benchmark results on their official blog and in their developer documentation. According to the data released by the company on April 28, GPT-4.1 achieved a score of 54.9 percent on the SWE-bench Verified benchmark. That is the gold standard for measuring an AI model's ability to solve real world software engineering tasks. For context, GPT-4o scored 33.3 percent on the same benchmark. GPT-4o with the January 20, 2025 update scored 38.6 percent. So we are looking at a jump of roughly 16 percentage points over the previous best GPT-4o checkpoint. That is not a tweak. That is a rewrite.
But the GPT-4.1 performance improvements extend far beyond software engineering. On the Multi Challenge benchmark for instruction following, GPT-4.1 scored 86.1 percent compared to 79.2 percent for GPT-4o. On the Video MMMU benchmark, which tests multimodal understanding of video content, GPT-4.1 hit 72.7 percent versus 69.7 percent for GPT-4o. And on agentic coding tasks measured by the SWE-bench Multilingual benchmark, GPT-4.1 crushed it at 67.1 percent compared to 46.9 percent for GPT-4o. Every single metric moved up. And some moved up by a lot.
Here is the part they did not put in the press release. These gains are not coming from some secret new architecture. OpenAI has not invented a new type of neural network here. The GPT-4.1 performance gains come from a brutal, meticulous focus on training data quality, post training optimization, and a massive expansion of the context window to one million tokens. One million tokens. That is roughly 750,000 words. That is the entire text of the Harry Potter series plus a few extra books. You can now feed an entire codebase into a single prompt and the model will not forget the beginning by the time it reaches the end. That is the big structural change that makes the benchmark numbers possible.
What One Million Tokens Actually Means for You
Let me make this practical. If you are a developer, you have been living in a world where you have to chunk your code into pieces, summarize each piece, and then stitch the summaries together to get a model to understand your full application. That process is error prone, expensive, and slow. With a one million token context window, you can dump your entire repository into a single API call. The model can then reason across the whole codebase at once. It can find a bug in file A that is causally linked to a function in file B that references a variable in file C. That was essentially impossible before. Now it is the default.
"Our research shows that GPT-4.1 maintains strong performance even when the context is packed to 950,000 tokens. The model does not exhibit the sharp degradation in accuracy that we saw in earlier models when the context window was filled."
Source: OpenAI official documentation published April 28, 2025
The GPT-4.1 performance in long context retrieval tasks is the most technically impressive part of this release. On the Mr. HRE benchmark, which tests a model's ability to find a specific piece of information buried in a massive context, GPT-4.1 scored 34.7 percent. That does not sound impressive until you realize that GPT-4o scored only 10.2 percent on the same test. The model is more than three times better at finding a needle in a haystack that is one million tokens tall. That is the kind of improvement that changes what you can actually build with this technology.
The Price War Nobody Is Talking About
Here is where the story gets interesting in a very different way. OpenAI is not just giving you more capability. They are charging you less for it. GPT-4.1 costs $2 per million input tokens and $8 per million output tokens. The older GPT-4o costs $2.50 per million input tokens and $10 per million output tokens. So you are getting a significantly better model for roughly 20 percent less money. That is an unusual dynamic in the technology industry. Usually you pay more for the new thing. The GPT-4.1 performance improvements are accompanied by a price cut, which tells you two things. First, OpenAI has found real efficiencies in their inference pipeline. Second, they are feeling the competitive heat from Google with Gemini 2.5 Pro, from Anthropic with Claude Opus 4, and from a dozen open source models that are getting dangerously good.
Let me break down the pricing math for you because it matters for anyone building products on top of these APIs.
- GPT-4.1: $2 per million input tokens, $8 per million output tokens. One million token context window. Best for complex coding, long document analysis, and agentic workflows.
- GPT-4.1 mini: $0.40 per million input tokens, $1.60 per million output tokens. 1 million token context window. Best for high volume classification, summarization, and lighter agent tasks.
- GPT-4.1 nano: $0.12 per million input tokens, $0.48 per million output tokens. 1 million token context window. Best for cheap, fast classification and simple extraction tasks.
The GPT-4.1 performance to price ratio is genuinely disruptive. If you are running a startup that processes millions of API calls per day, switching from GPT-4o to GPT-4.1 could save you thousands of dollars per month while simultaneously making your product better. That is not a trivial calculation. That is a business model shift.

The Skeptic's View: What Is OpenAI Hiding?
But wait. I have been doing this long enough to know that every major AI release comes with a shadow. And the shadow on the GPT-4.1 performance story is significant. First, let us talk about what is not included in the benchmarks. OpenAI has not published independent safety evaluation results for GPT-4.1 in the same detail they provided for GPT-4o. They released a system card, but independent researchers I spoke with who asked not to be named because they are under NDA with OpenAI said the safety documentation is thinner than expected for a model with this much capability.
Second, and this is a big one for developers: GPT-4.1 is API only. You cannot access it through ChatGPT. The chat interface still runs on GPT-4o and GPT-4o mini. So if you were hoping to replace your daily ChatGPT assistant with the smarter model, you are out of luck. This is a developer focused release. OpenAI is clearly segmenting their product lines. The consumer product gets the old model. The paying API customers get the new model. That strategy makes business sense but it also creates a weird two tier system where the general public does not get access to the best technology.
The Unnecessary Refusal Problem
There is another subtle but important improvement in the GPT-4.1 performance that OpenAI is quietly proud of. The model refuses to answer prompts far less often than GPT-4o. This has been a massive pain point for developers who use these models for work. GPT-4o developed a reputation for being overly cautious, refusing to answer perfectly innocuous questions about code, medical information, or even straightforward technical tasks. OpenAI claims they have dramatically reduced unnecessary refusals in GPT-4.1. They are calling it "improved refusal behavior" in their documentation. That is the corporate euphemism for "we broke the guardrails too hard and now we are trying to find the right balance."
"We have made significant progress in reducing unnecessary refusals while maintaining the safety bar for genuinely harmful content. GPT-4.1 shows a 45 percent reduction in incorrect refusals on our internal evaluation set compared to GPT-4o."
Paraphrased from OpenAI's official release documentation, April 28, 2025
Here is the tension that keeps me up at night. A model that refuses fewer requests is a more useful model. But a model that refuses fewer requests is also a model that will say yes to more dangerous requests. OpenAI claims they have maintained the safety bar. Independent researchers are not so sure. The GPT-4.1 performance improvements come with a higher surface area for potential misuse, and the company has not been fully transparent about the edge cases. That is not a conspiracy theory. That is a historical pattern we have seen with every single major AI release since GPT-3.
The Real World Impact: Who Wins and Who Loses
Let me tell you who wins with the GPT-4.1 performance leap. AI startups that are building agentic coding tools win. Companies like Cursor, Replit, and GitHub Copilot can now offer their users a model that actually understands an entire codebase. That is a qualitative change in what is possible. If you are building a tool that writes code, tests it, deploys it, and debugs it, the one million token context window is the single most important technical capability you can have. GPT-4.1 makes that work.
Enterprise customers who process huge volumes of legal documents, medical records, or financial reports also win. You can now feed an entire contract into a single prompt and ask specific questions about clause 47 in the context of clause 12 and the definition section at the start. The model will handle that without losing track. That is a workflow that used to require a team of paralegals and a week of time. Now it takes one API call and thirty seconds.
Who loses? The hardware companies lose. Running a one million token context window requires enormous amounts of GPU memory. The inference cost is lower per token, but the peak memory usage is higher. If you are running your own infrastructure on premise, you are looking at a hardware upgrade. And if you are a cloud provider that is not OpenAI, you are looking at a competitive gap. The GPT-4.1 performance leadership means that any company relying on a different model provider is now running a second place product. That is a brutal position to be in.
The Mini and Nano Models: The Real Strategic Play
I want to spend a moment on GPT-4.1 mini and GPT-4.1 nano because I think they are actually more important strategically than the flagship model. GPT-4.1 mini is cheap. Really cheap. At $0.40 per million input tokens, it is competitive with models like Claude Haiku and Gemini 1.5 Flash. But GPT-4.1 mini has a one million token context window, which neither of those competitors match at this price point. And the GPT-4.1 performance on the mini version is still strong enough for most real world tasks. On the MMLU benchmark, GPT-4.1 mini scored 87.0 percent. That is within striking distance of GPT-4o's score of 88.7 percent, but at a fraction of the cost.
GPT-4.1 nano is even more interesting. At $0.12 per million input tokens, it is the cheapest model OpenAI has ever offered with a one million token context window. It is designed for simple classification tasks: spam detection, sentiment analysis, content moderation, and basic data extraction. The fact that you can now do those tasks with a one million token context window is absurd. You can classify an entire customer support conversation history in a single call for less than one cent. That changes the economics of customer service automation.
Here is the strategic logic. OpenAI is not just selling you a better model. They are selling you a tiered system where the same architecture scales from nano to full, and all three tiers share the same one million token context window. If you build your application on GPT-4.1 nano, you can upgrade to GPT-4.1 full without changing any of your prompt engineering. The API interface is identical. The context window is identical. Only the capability and the price change. That is a lock in strategy, and it is a good one. The GPT-4.1 performance consistency across the tiers makes it easy to start small and scale up without rewriting your entire application.
The Competition Is Not Standing Still
I have to mention the competitive context because it is impossible to understand the GPT-4.1 performance leap without understanding who is chasing OpenAI. Google released Gemini 2.5 Pro earlier this year with a one million token context window and it is genuinely strong. Anthropic released Claude Opus 4 with a 200,000 token context window and exceptional instruction following capabilities. Open source models like Llama 4 and DeepSeek V3 have been closing the gap on coding benchmarks. OpenAI needed to respond, and they responded with force.
But there is a catch that every developer needs to understand. The GPT-4.1 performance improvements are concentrated in English language tasks and in code tasks. The multilingual benchmarks show smaller gains. If you are building a product for a non English speaking market, your mileage may vary significantly. And the multimodal capabilities, while improved, still trail what Google has done with Gemini 2.5 Pro on video understanding and image generation integration. OpenAI is winning on coding and long context. They are not winning on everything.
Let me give you the full list of where the GPT-4.1 performance truly dominates and where it merely catches up.
- Dominates: Software engineering (SWE-bench), long context retrieval (Mr. HRE), instruction following (Multi Challenge), agentic coding (SWE-bench Multilingual)
- Catches up: Video understanding (Video MMMU), multimodal reasoning, multilingual tasks, mathematical reasoning (MATH)
The model is a specialist that happens to be very good at general tasks. That is a useful distinction. If you are building a coding agent, a document analysis tool, or a long form reasoning system, GPT-4.1 is the best option on the market right now. If you are building a multimodal creative tool or a multilingual customer service bot, you should still evaluate the alternatives.
The Unanswered Question: Is This a Real Leap or Just Better Data?
Here is the question that the technical community is fighting about on social media and in private channels

Elena Vance reports on artificial intelligence, from frontier research labs to the products reshaping everyday work. She focuses on how machine learning is moving out of the lab and into the real world, and what that shift means for readers.
💬 Comments (0)
No comments yet. Be the first!