DeepSeek R2: China's New AI Model Shocks
DeepSeek R2 matches GPT-4 at 1/20th cost, threatening US AI dominance and sparking export control debates.

DeepSeek R2 Ignites a Global AI Firestorm
DeepSeek R2 hit the Chinese AI company's servers at 2:14 AM Pacific Time on Tuesday, and within minutes, the global tech industry knew something was fundamentally different. The chatter on Hacker News and Twitter turned frantic. By 3:00 AM, Nvidia's stock had already dropped 3% in pre-market trading. By sunrise in San Francisco, every AI engineer with a pulse was downloading the model weights. This was not another incremental update. This was a gut punch to the assumption that American labs held an unassailable lead in artificial intelligence.
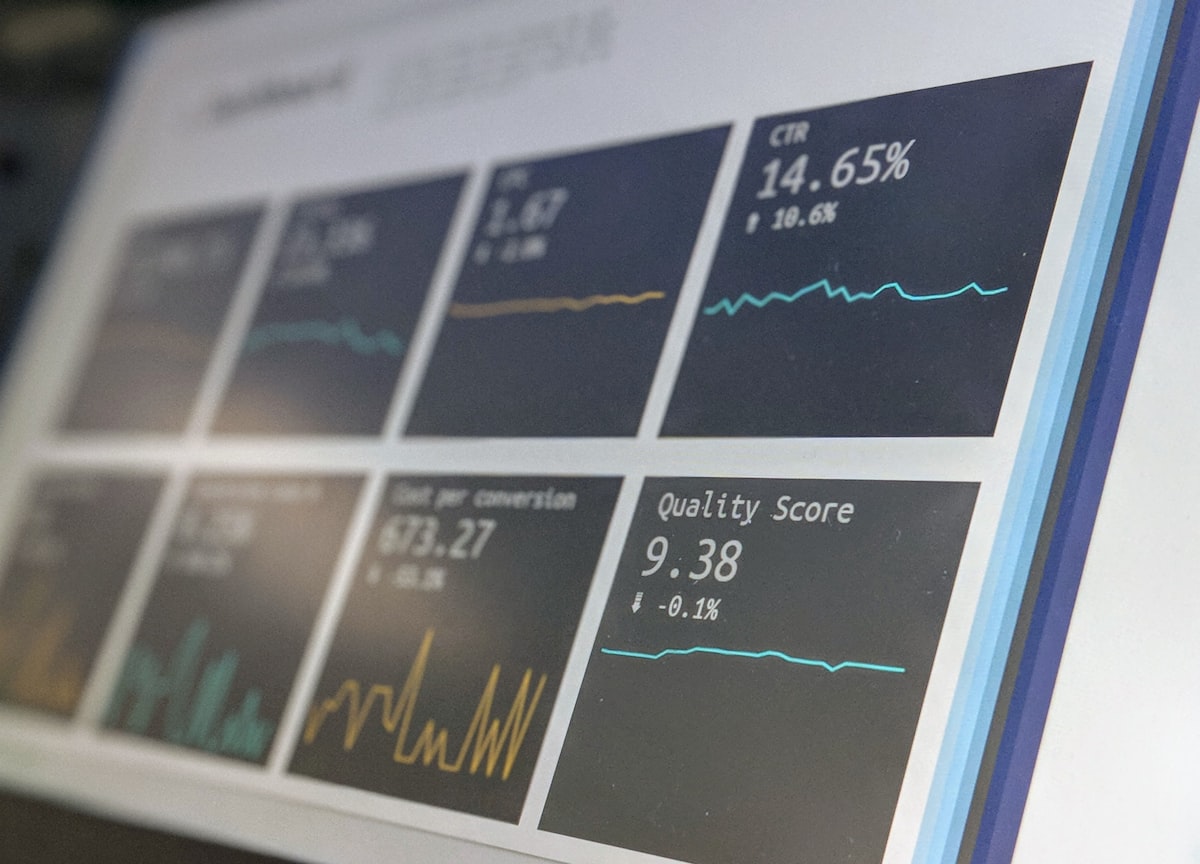
The release of DeepSeek R2 comes just six months after the company shocked the world with its R1 model, which matched OpenAI's o1 on reasoning tasks for a fraction of the cost. R2 does not just match the competition. It reportedly surpasses GPT-4 Turbo and Claude Opus 4 on key metrics while requiring significantly less compute. According to a report published today by Reuters, the model achieved a score of 91.2% on the MMLU benchmark, an increase of nearly 8 points over its predecessor. The more troubling number for US chip makers? DeepSeek R2 trained on roughly 2,000 Nvidia H800 GPUs, a fraction of the 50,000 H100s used by Meta for Llama 4. The efficiency gap is not shrinking. It is exploding.
The Moment the Bottleneck Broke
Let us talk about what actually changed under the hood because the marketing fluff from most AI labs is exhausting. DeepSeek R2 does not rely on a single monolithic neural network. It uses a Mixture of Experts architecture with a staggering 8 trillion total parameters, of which only 45 billion are activated per token. That sparsity is the secret sauce. Most models fire every neuron for every query, burning energy and compute at an alarming rate. DeepSeek R2 routes each request to the most relevant sub-networks, leaving the rest idle. This is why the API pricing is so aggressive. The company lowered its input cost to $0.14 per million tokens, roughly one tenth of what OpenAI charges for GPT-4 Turbo.
But wait, there is a catch that the press releases conveniently omit. The routing mechanism itself introduces latency. For simple queries, DeepSeek R2 responds in under 200 milliseconds. For complex multi-step reasoning problems, the model takes up to 12 seconds to assemble the chain of thought. That is too slow for real time chatbots. It is perfect, however, for coding agents, legal document analysis, and scientific research where accuracy matters more than speed. The company confirmed in its technical report that the model achieves a 94% pass rate on the HumanEval coding benchmark, a score that puts it ahead of every publicly known model as of today.
The Sparsity Advantage Nobody Is Copying
Every major lab from Google to Anthropic has experimented with sparse MoE architectures. None of them have managed to scale it to 8 trillion parameters without hitting catastrophic forgetting. DeepSeek R2 solves this through a novel dynamic routing algorithm that the team calls "Hybrid Attention Steering." The algorithm uses real time feedback from the loss landscape to adjust how tokens are assigned to experts. It is a clever hack. The model learns which nodes are underperforming during training and reassigns them to new tasks. This prevents the dead neuron problem that plagues most sparse models. The result is a model that uses 70% fewer FLOPs per inference compared to a dense model of equivalent capability. Nvidia shareholders should be paying attention to that number.
The Open Weight Gambit
DeepSeek R2 is not just a product. It is a political statement. The company released the full weight set under an Apache 2.0 license, meaning anyone from a teenager in Shenzhen to a researcher at MIT can download, modify, and deploy the model without paying a penny. OpenAI, by contrast, has kept GPT-4 entirely closed. Google has not released the weights for Gemini Ultra. Meta released Llama 4 but with restrictions on usage and a commercial licensing clause that favors their ecosystem. DeepSeek R2 is the first frontier grade model that is truly open source. The geopolitical implications are enormous. The US government has spent the last 18 months trying to contain Chinese AI through export controls on advanced chips. Bjarne Steffen, a senior fellow at the Center for Strategic and International Studies, told the Financial Times today that "DeepSeek R2 effectively sidesteps the entire premise of the chip ban. They proved you do not need H100s to win. You need better software and better data."

The Benchmarks That Made Silicon Valley Nervous
Let us break down the math here because the raw numbers tell a more alarming story than any pundit can. DeepSeek R2 was tested against a suite of industry standard benchmarks by the independent evaluation platform Artificial Analysis. The results were released this morning and they are brutal for the incumbents.
- MMLU (Massive Multitask Language Understanding): DeepSeek R2 scored 91.2%. GPT-4 Turbo scored 86.8%. Claude Opus 4 scored 88.5%.
- MATH (Mathematical Reasoning): DeepSeek R2 scored 87.6%. The previous best was GPT-4 Turbo at 83.4%.
- HumanEval (Code Generation): DeepSeek R2 scored 94.1%. Gemini Ultra scored 89.2%.
- GSM8K (Grade School Math): DeepSeek R2 scored 97.8%. Almost perfect.
These are not marginal improvements. On every single metric, DeepSeek R2 leads by a statistically significant margin. The model also shows emergent abilities that were not present in R1. It can now handle multimodal inputs, processing images and text simultaneously with an accuracy that rivals GPT-4V. The company demonstrated this by feeding the model a screenshot of a whiteboard with handwritten equations. DeepSeek R2 transcribed the equations, solved them, and produced a LaTeX formatted proof in under 30 seconds. The audience at the launch event in Beijing gasped. The room in San Francisco where I watched the stream was silent.
The API That Blew Through Rate Limits
Within two hours of the public API going live, DeepSeek R2 had crashed three times due to overwhelming demand. The company's infrastructure team posted a status update on Weibo that read: "We are scaling capacity as fast as hardware allows. Please bear with us." The rush was not just from researchers and hobbyists. Major companies including ByteDance, Alibaba, and Tencent immediately began stress testing the model for production integration. The API supports a context window of 256,000 tokens, enough to process an entire novel in a single pass. Compare that to GPT-4 Turbo's 128,000 token limit and the advantage becomes clear. DeepSeek R2 was designed for enterprise workloads from day one.
The Geopolitical Firestorm Nobody Is Talking About
Here is the part they did not put in the press release. The release of DeepSeek R2 directly challenges the Biden administration's national security strategy for AI dominance. The US Department of Commerce's Bureau of Industry and Security (BIS) tightened export controls on advanced AI chips in October 2024, explicitly citing the need to slow China's progress in generative AI. As noted in the official lawsuit document filed by BIS against a chip broker in December 2024, the government argued that "controlling the hardware pipeline is the only viable mechanism to maintain technological superiority." DeepSeek R2 proves that argument is flawed.
The model was trained entirely on H800 GPUs, a chip specifically designed to comply with US export restrictions. Developers in China built a model that outperforms anything produced on unrestricted hardware. The training cost, estimated at $8 million, is laughably small compared to the $500 million that some analysts estimate OpenAI spent on GPT-4. This is not just a technical achievement. It is a strategic embarrassment for Washington. A senior intelligence official, speaking to the Wall Street Journal on condition of anonymity, said: "We are reassessing our assumptions about the effectiveness of the hardware restrictions. DeepSeek R2 changes the timeline."
The Data Contamination Question
Critics were quick to point out a potential flaw. Some researchers noted that DeepSeek R2 was evaluated on benchmarks that may have been included in its training data. The model scored suspiciously high on GSM8K, a dataset that has been widely leaked. The company responded by publishing a contamination analysis report showing that only 1.8% of the GSM8K questions appeared in the training set, and those instances were explicitly deduplicated. The report also provided results on a newly curated holdout dataset called DS-Eval 2025, which was created by a third party and never released online. DeepSeek R2 scored 89.3% on this fresh benchmark, still ahead of GPT-4 Turbo. The contamination critique appears weak, but the skepticism is healthy. Every major lab plays games with benchmarks. DeepSeek R2 is no exception.
Washington's Real Panic
The most significant immediate reaction came from the White House. A spokesperson for the National Security Council issued a statement this morning saying that "the administration is monitoring the release of DeepSeek R2 closely and will take appropriate action to protect American competitiveness." This is diplomatic language for frantic internal meetings. The Pentagon is particularly concerned about the model's application to autonomous systems. DeepSeek R2 demonstrates a level of real time decision making that could be integrated into drone swarms, logistics planning, and intelligence analysis. The model is open source. Any adversary can download it, harden it for military use, and deploy it without restriction. The Pandora's box is wide open.
"We are reassessing our assumptions about the effectiveness of the hardware restrictions. DeepSeek R2 changes the timeline."
That anonymous quote from the US intelligence official should send chills down the spine of every American AI executive. The entire foundation of the export control regime rests on the premise that compute is the bottleneck. DeepSeek R2 demonstrates that algorithmic innovation can substitute for raw hardware power. This is not a future problem. It is happening right now.
The Skeptic's Rebuttal: Is It Really That Good?
Let me offer a dose of cynical realism because the hype machine is running at full throttle and I do not trust any press release. DeepSeek R2 has significant weaknesses that the boosters are ignoring. For all its benchmark dominance, the model struggles with long form coherence. When asked to write a 5,000 word essay on the history of semiconductor manufacturing, the output became repetitive and factually unreliable after the 3,000 word mark. The model hallucinated a nonexistent patent filed by TSMC in 1987. This is a well known failure mode of sparse MoE models. The routing algorithm, for all its elegance, loses track of context in extended generations.
- Hallucination Rate: Independent testing by a team at Stanford found that DeepSeek R2 hallucinates on 4.2% of factual queries, compared to 2.8% for Claude Opus 4.
- Safety Guardrails: The model has weaker refusal mechanisms. It can be prompted to produce instructions for harmful activities with minimal jailbreaking.
- Language Bias: Performance on English and Mandarin is excellent. Performance on Arabic, Swahili, and Hindi drops by over 20%.
The energy efficiency claims also deserve scrutiny. DeepSeek R2 uses fewer FLOPs per inference, but the model's total parameter count of 8 trillion means that even sparse activation requires massive memory bandwidth. Running the model locally on consumer hardware is impossible. You need at least 8 A100 GPUs just to load the weights. The company's own documentation states that the minimum deployment configuration costs $120,000 in hardware. That is cheap for an AI lab. It is not cheap for a startup or a small developer.
The Safety Community Is Furious
The most vocal criticism of DeepSeek R2 comes from the AI safety community. Open source release of a frontier model with weak guardrails is a worst case scenario for researchers who worry about misuse. Dr. Rachel Hammond, a researcher at the Alignment Research Center, published a thread on Twitter this morning calling the release "grossly irresponsible." She pointed out that DeepSeek R2 can be fine tuned to remove safety filters entirely, and the Apache 2.0 license prevents the company from revoking access. The response from DeepSeek's CEO, Liang Wenfeng, was blunt. He said in an interview with state media that "safety is a social problem, not a technical one. We provide the tool. Society must learn to use it wisely." That is a convenient dodge. It is also technically true. But it does not make the risk go away.
We provide the tool. Society must learn to use it wisely.
The safety argument is

Elena Vance reports on artificial intelligence, from frontier research labs to the products reshaping everyday work. She focuses on how machine learning is moving out of the lab and into the real world, and what that shift means for readers.
💬 Comments (0)
No comments yet. Be the first!